还在用 DragGAN、DragDiffusion 拖拽修图?点选拖拽容易变形、边界割裂、细节丢失的时代落幕了!ECCV 2026 ICRDrag 首创上下文区域拖拽模型,用掩码精准定位局部区域,移动、缩放、变形全都丝滑自然,兼顾精准度与画面真实感。

Paper: https://arxiv.org/pdf/2606.25907
GitHub: https://github.com/bcmi/ICRDrag-Region-Drag-Editing
Demo: https://drag.ustcnewly.com/
效果展示
先看编辑效果,每一组图像左边蓝色掩码是源区域,右边红色掩码是目标区域。拖拽编辑旨在把源区域拖拽到目标区域,其他区域除了必要的跟随性改动 (比如嘴巴动了,下巴也要跟着动) 之外,细节尽量保持不变。可以看出 ICRDrag 对于各种类型图片的姿态和形状调整都能轻松拿捏。

下面视频是 demo 展示,用户可以用不同颜色画出多对源区域和目标区域 (目前最多支持 5 对),把多个源区域拖拽到对应的目标区域。如果其他区域出现了不想要的改动,可以在其他区域增加类似锚点的源区域和目标区域,锁定其他区域。
体验链接:https://drag.ustcnewly.com/
直击痛点
传统拖拽修图,到底有多难用?玩过 AI 拖拽编辑的朋友一定踩过这些坑:
基于单点拖拽:
主流点拖拽模型比如 DragGAN, DragDiffusion 仅靠少量点对控制画面。点对信息模糊,AI 经常猜不透你的想法。点越少歧义越大,想要精准调整物体形态基本靠碰运气,很难严格对齐目标位置。
现有区域拖拽:
后来出现的 RegionDrag, DragFlow 等模型改用掩码控制区域,但缺陷依旧明显:物体拖拽后边缘断层,和背景融合生硬;复杂的形状姿态调整完全 hold 不住。

上下文区域拖拽
本次 ECCV2026 提出的 ICRDrag(In-Context Region-based Drag)全新解法:上下文区域拖拽,真正实现「选啥改啥」。
上下文学习框架:
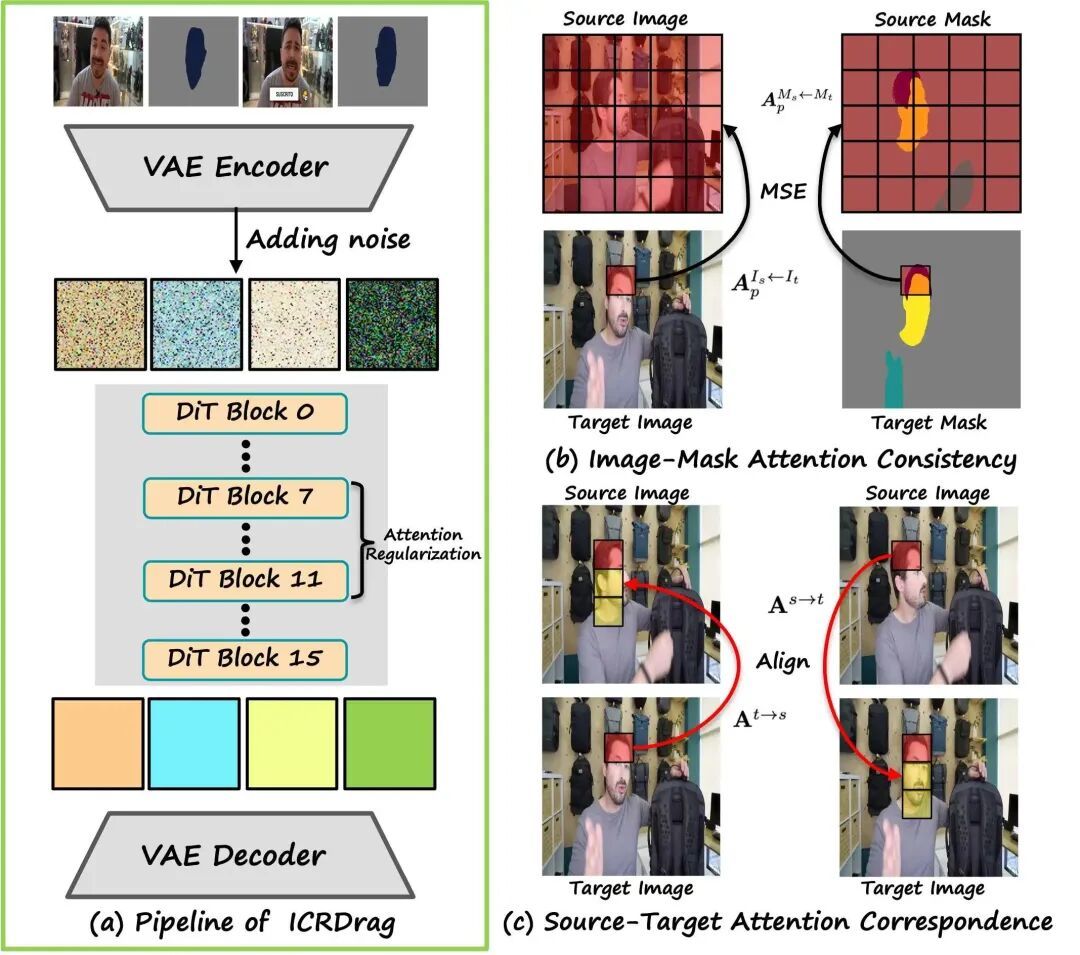
基于 DiT 上下文学习框架,一次性输入原图、源区域掩码、目标区域掩码,直接输出编辑完成的图片,从底层解决拖拽编辑的控制难题。
图像 - 掩码注意力一致性约束:
目标图像在借鉴原图信息时,注意力分布必须和目标掩码匹配源掩码的分布保持一致。AI 不再割裂看图片和选区,生成画面严格贴合掩码划定的空间轮廓。
源 - 目标双向注意力对应约束:
目标物体看向原图对应区域,原图区域也反向关注目标物体,建立编辑前后物体的对应关系。
图片 / 掩码专属模态 LoRA:
图像富含纹理细节,掩码仅存储空间轮廓,二者的性质差别很大。ICRDrag 为图像、掩码分支使用独立 LoRA。
分阶段课程式训练:
现实使用中,用户勾勒的掩码往往比较粗糙。模型采用两阶段渐进式训练:第一阶段用完整语义掩码训练,让模型学会区域变换逻辑;第二阶段用稀疏不完整掩码训练,随机膨胀模拟手绘粗糙选区,大幅提升模型容错率。哪怕掩码画得潦草,AI 依旧能精准理解你的编辑意图。
区域拖拽大规模数据集
为了训练 ICRDrag 模型,该工作基于百万级视频数据集 OpenVid,打造了首个大规模区域拖拽数据集 PRD (Paired Region Dataset),补齐领域空白:
训练集:28.7 万组「原图 + 源掩码 + 目标图 + 目标掩码」配对样本,如下图所示。下图中,左栏是原图、源掩码、从源掩码采样的部分区域,右栏是目标图、目标掩码、从目标掩码采样的部分区域。
评测基准 PRDBench:1000 组人工校验高质量样本,同时标注掩码 + 关键点,可公平对比点拖拽、区域拖拽两类模型。

应用场景
图像拖拽编辑覆盖多个落地场景,是广大设计师和摄影爱好者的福音。
人像修图:框选人脸、四肢,随意调整身材比例、姿态、五官位置,不变形不失真;
静物 / 产品设计:拖拽商品调整摆放位置、缩放大小,无需重绘光影;
场景构图优化:移动画面中人物、花草、建筑,自动填充背景,画面无缝融合;
创意设计:自由扭曲物体轮廓,实现复杂创意形变,告别生硬拼接。
实验室简介
ICRDrag 出自上海交通大学牛力实验室。该实验室近几年主要工作集中在图像生成和编辑领域,代表性子领域是图像合成 / 物体插入 (image composition/object insertion) 和少样本图像生成 (few-shot image generation),也涉猎过图像填充、图像分层、风格迁移、拖拽编辑等其他子领域。近两年在关注生成模型的后训练和理解生成一体化模型。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com
胜亿优配提示:文章来自网络,不代表本站观点。